如何对一本书进行专家抽样阅读? #
1 #
我们在上一个技巧中提到了非概率抽样阅读中的便利抽样阅读法,其中讲到了从书内和书外寻找相应的抽样提示,在这些信号中,还有一种相对特殊的信号 —— 以「人」为核心的信号 —— 作为一个新手,我们可以直接听取某些专家的意见来帮我们快速定位一本书的核心内容,专家建议我们一本书的核心在哪里,我们就定位到这个章节快速开始阅读,这就是专家抽样阅读。
2 #
比如《情报分析心理学》这本书,在第一章开头,作者小理查兹 · J. 霍耶尔(Richards J. Heuer, Jr.)就向我们告知本书的重点是第八章:

比如雷科夫(George Lakoff)和詹森(Mark Johnson)合著的认知语言学入门必读书目《我们赖以生存的隐喻》,台湾版译者周世箴在「中译导读」中,就提出了本书的阅读指南:
本书论述体例不同于一般理论书籍,读者面向多元,前面三分之一篇章(1-10)浅显易懂,所举皆读者所熟悉的案例,初接触者很容易入门,而且会产生往裡鑽的动力。中间的三分之一(11-23)理论性开始加强,但难易适中,正好可以帮初入门的实践者解惑。最后的三分之一(24-30)开始触及源远流长的西方哲学传统,若要细究细察追本穷源,对于不熟悉西方哲学传统的读者,一个学说一个名称就可以扯一藤子瓜,而此书从头到尾无注释,想要全盘了解至少要参考一部西方哲学史外加一本西方语言学史。
简言之,周老师将整本书分成了三个部分:
| 部分 | 章节 | 阅读难度 |
|---|---|---|
| 1 | 1-10 | 浅显易懂 |
| 2 | 11-23 | 难易适中 |
| 3 | 24-30 | 难度稍高 |
参考这样的标准,就能快速根据自己对人资语言学的理解选择相应的部分展开阅读。
不仅如此,译者还对全书给出了对应的分类解析:
本书一开始便带领读者优游无所不在的譬喻,使读者觉得无拘无束,但其缺点便是散。本书共分三十章,而苏以文(2005),《隐喻与认知》将其概括为十一单元而加以论述,其与本书章节一一对应如下,颇能抓住本书的主线:
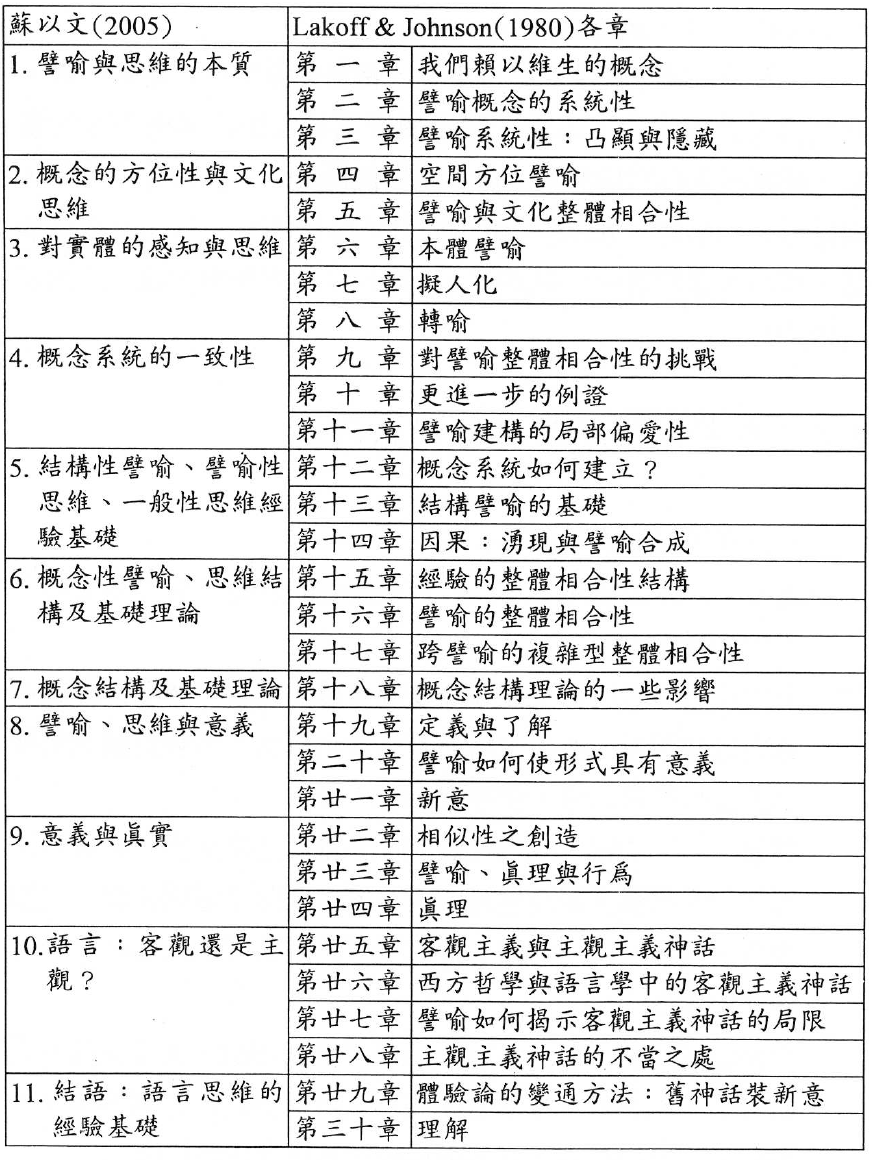
如果我们对《我们赖以生存的隐喻》这本书不知道从哪里读起,就可以参考周世箴老师的意见,从难读或者主题来抽样阅读。
又比如德国社会学家哈特穆特·罗萨(Hartmut Rosa)写了一本关于现代社会异化的社会批判著作《新异化的诞生》,中文版译者郑作彧老师在译者前言专门就这本书的读法进行了指导:
这是一本篇幅不算长的书,但内容却颇为丰富。其中一项丰富之处在于,它至少适合于两种读者,从两种角度来阅读。一种是喜欢有点学理内涵,但又无力消化艰深内容的普通读者;另一种是喜爱钻研社会理论的专业社会学家。当然,不同的读者用不同的读法来品鉴这本书,滋味就会不太一样。
……
因此我建议读者在阅读本书时,可以先从第一章和第三章读起。若尚有余力、且有兴趣的话,可以回过头来去挑战第二章。
所以我们可以对照序言中的分析,对应自己的阅读偏好,按照郑老师的方法启动阅读。
上述书本的作者小理查兹 · J. 霍耶尔、译者周世箴、郑作彧都是在情报分析领域、语言学、社会科学领域深耕多年的老师,他们就相当于行业专家,这些意见对于普通读者来说值得借鉴,所以我们就可以直接通过专家的意见进行抽样阅读。
当我们对某些领域缺乏足够知识了解,需要借助在该领域有较高技能或知识水平的人进行评估或发表意见时使用这种抽样策略。使用专家抽样就能够大大降低试错成本,以相对科学的方法启动阅读,抓住书本核心。
简单来说,专家抽样分为两个基本步骤:
- 确定专家标准。
- 选择专家意见。
而在现实情境中,可能经常会碰到「伪专家」,比如很多电视网络媒体上会出现种种人,他们往往声称自己是某领域专家,但其意见极有可能存在各种偏见与谬误。如果盲目跟随,就会为其缴纳各种智商税。
从阅读一本书的角度,如何规避这种现象?
一个简单的识别策略就是审查建议者与作者是否为同行、建议者在这个领域的社会评价如何。
以《认知天性》这本书为例,这是一本面向大众介绍如何有效学习的实证研究指南。
中文版中出现了两篇推荐序,序一作者为樊登读书会创始人,序二作者是TED演讲中国引进人。
而《认知天性》这本书的主要作者亨利·L·罗迪格三世(Henry L. Roediger III) 是研究人类学习和记忆领域的美国心理学家、华盛顿大学心理学教授,H指数124。毫无疑问,中文版的两位作序者身份和本书作者身份存在较大偏离。《认知天性》中文版请这两位作序,反而是借助他们在各自领域的影响力来推广这本书。从这本书核心章节确认的角度,其意见并无多大的参考价值。
如果我们拿到的书并没有针对核心章节推荐的信息,也没有找到具体的专家对阅读的推荐,应该如何处理呢?
我们可以通过人工智能来解决,比如用ChatGPT帮助我们推荐优先阅读的章节。
假设我们现在要阅读《改变》这本书,我们可以将整本书电子版提交给GPT,然后向GPT请教:

GPT如是回答:

这样,我们就相当于:
- 让GPT扮演了《改变》的作者Paul Watzlawick
- 模拟了一个前提(读者没有足够的时间)
- 让他重点推荐优先阅读的章节
从而获得了我们想要的答案:第一章、第三章和第七章。
更高阶的身份判断,可以参考阳老师在《聪明的阅读者》第十章中提到对作者的社会评价方面的叙述,它能够帮助我们识别作者、作序者等身份角色的高低,进而判断谁的建议更值得我们参考。
3 #
专家抽样的图示可以简化如下:
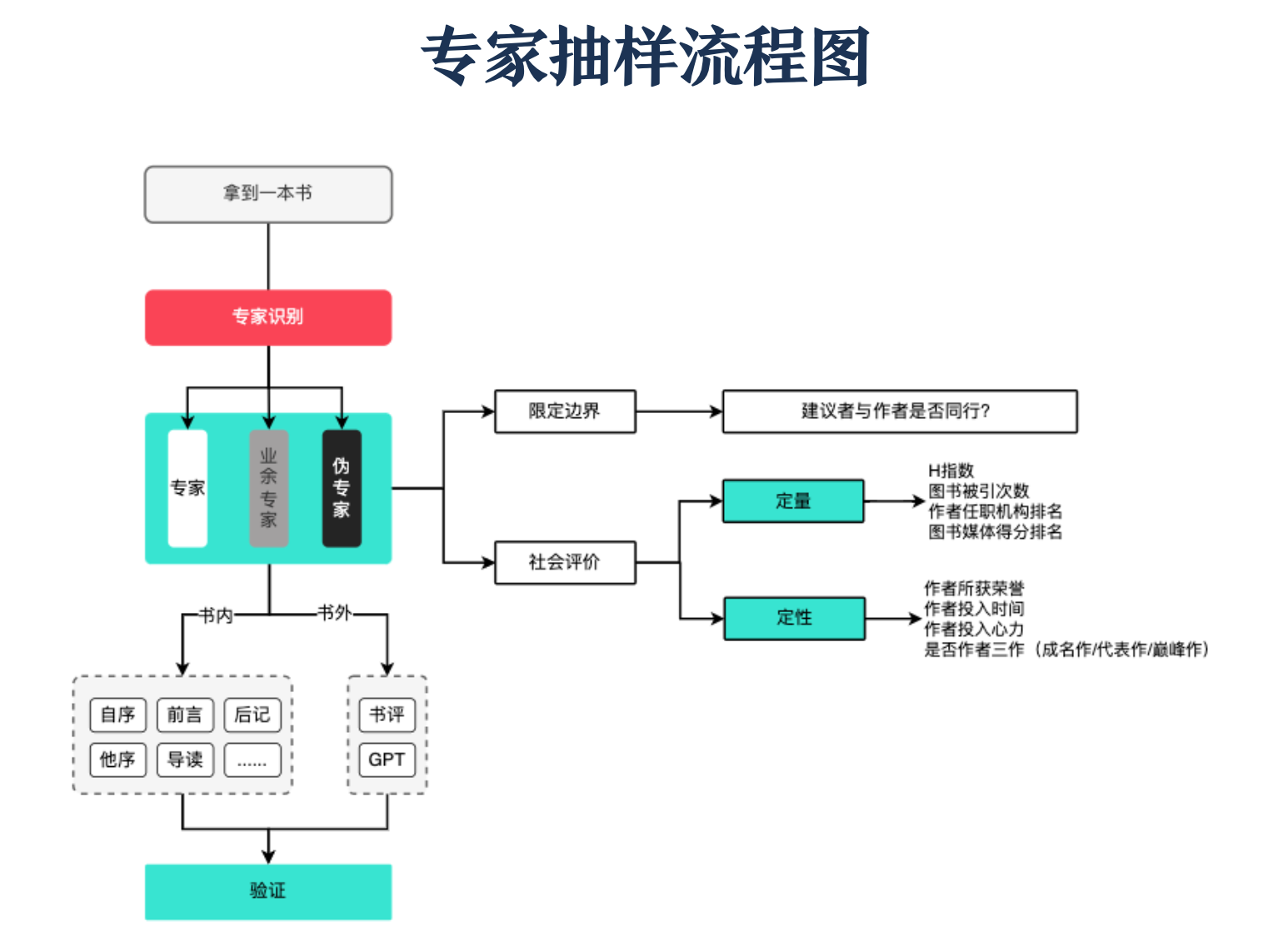
通过上述拆解发现,专家抽样的优势在于通过快速采纳意见进入阅读状态,节约试错成本。与之对应的缺陷是如果缺少对专家身份的审核,可能陷入抽样的偏差。所以在专家抽样之后,建议结合其他概率抽样方式进行验证,以规避可能出现的问题。