如何对一本书进行配额抽样阅读? #
1 #
前面我们学习了分层抽样,理解了分层抽样的三个基本步骤:
- 将全书的章节进行分组
- 对各组章节进行随机抽样
- 汇总抽样的章节展开阅读
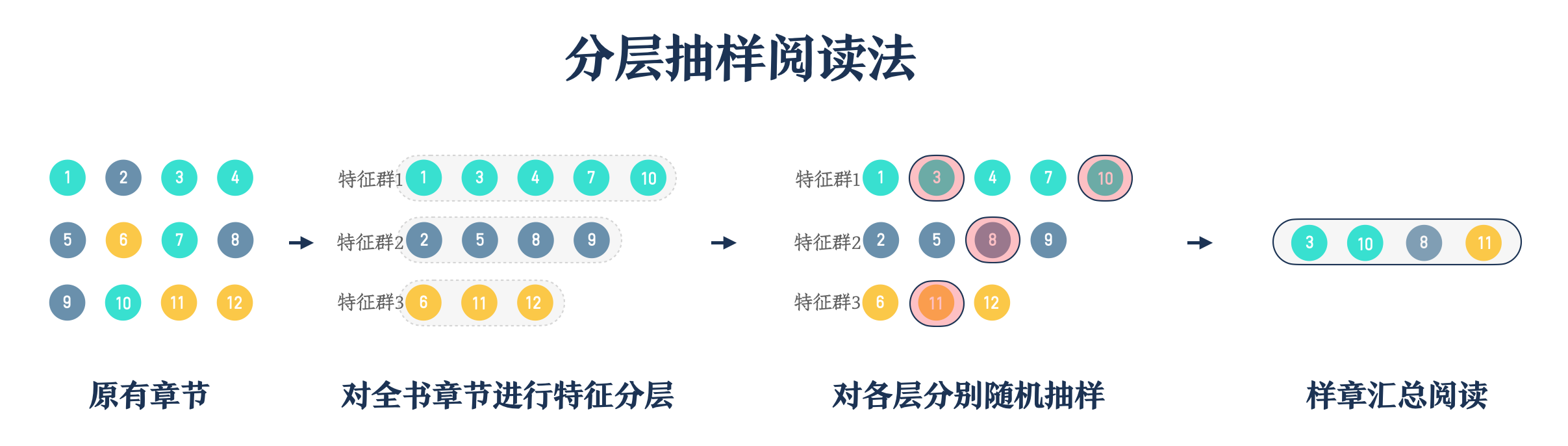
在这个过程中的第二步,分层抽样遵循的是随机性,确保分组后的每个章节都有相等的概率被选中,这种方法的优势在于它减少了抽样偏差,提高了抽中样章在组内的代表性,避免认人为干预。但在现实阅读情境中,我们主观上可能对刚分好层的章节产生一定兴趣或需求,我们不需要在通过随机抽样的方式,而是根据自己的兴趣或我们拥有的便利条件等方式直接选取相应的章节开始阅读,这就是配额抽样与分层抽样的关键区别。
换句话说,配额抽样是一种非概率抽样方法,我们将整本书划分为基于特定特征或主题的多个子群体(层)后,根据每个子群体在整体中的重要性或比重,人为地选择一定数量的章节进行阅读。
配额抽样阅读的使用前提 #
配额阅读抽样往往在下述前提下使用:
- 对某本书感兴趣,但是对这本书并没有太细致的了解。
- 阅读的时间与精力比较有限,没有阅读的充裕时间或情境,但又特别想阅读某些书。
- 尚不太具备复杂概率抽样或复杂非概率抽样的前提条件。比如没有找到专家对某本书的阅读建议或者对分层抽样方法不太熟悉。
2 #
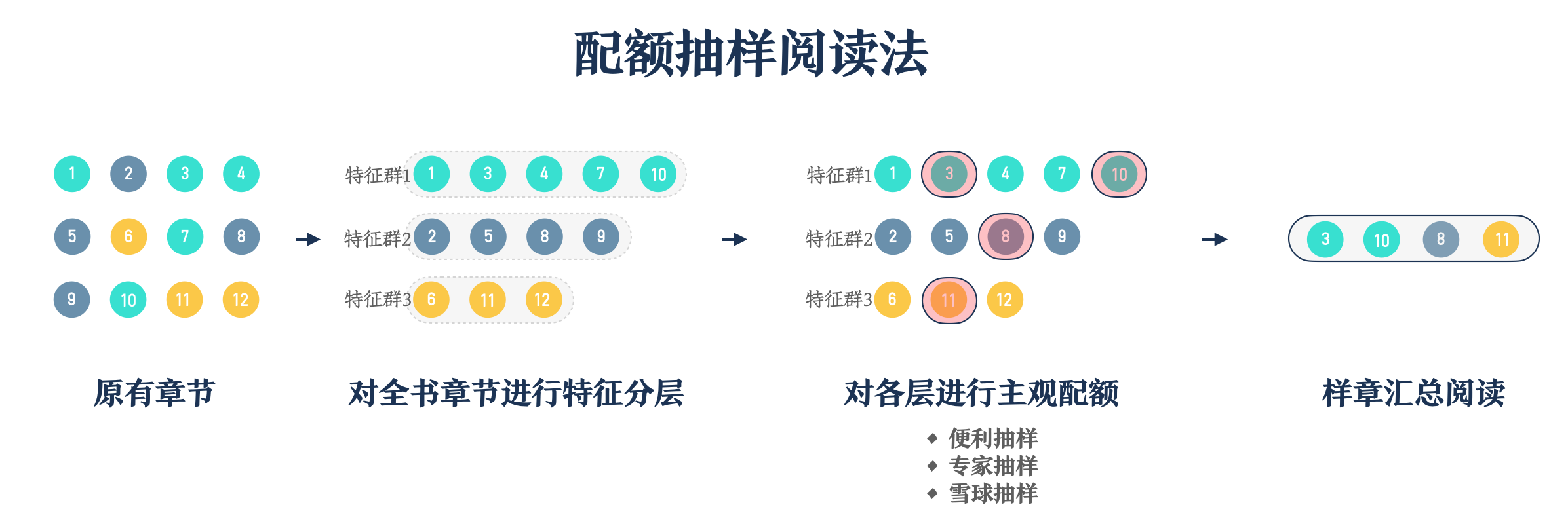
配额抽样简单来说可以分为三步:
1. 将全书分成不同的层级 #
由于配额抽样是一种非概率的抽样方法,所以在整个过程中,我们的主观意识起到了主要引领作用比如豆瓣网友@行动社交找潇潇 对《聪明的阅读者》一书的书评第一句话是这样的:

这种阅读策略就可以简单理解她采用了配额抽样的阅读思路 —— 将《聪明的阅读者》分成卡片类与非卡片类两组,这就是一种简单的分层。
又比如《儿童心理学》这本书,通过查看目录我们可以将其简单归类为「情境学习」和「知识学习」两个主要维度:

类似这种分类相比分层阅读的分类来说,会更加主观、灵活且快速。当然我们在这一步还可以借助便利抽样、专家抽样的方式对全书进行分组。
2. 为不同的层级确认一个配额 #
依旧以前面的《儿童心理学》为例,如果按照原来的分层阅读抽样的话,我们接下来就要对「情境学习」和「知识学习」两个章群进行随机抽样,但在配额抽样中,我们可以更加主观地去决定配额 —— 我们一共阅读3章。而这里的「3」,就是我们对《儿童心理学》这本书的主观配额设定。
接下来,我们对于前面的「3」就要在「情境学习」和「知识学习」两个章组中去分解,比如我们主观上决定阅读第三章和第四章、而对于「知识学习」组,我们主观上决定第五章,然后我们就开始阅读自己制定的章节了。
除此之外,我们在这一步的操作还可以借助便利抽样、专家抽样、雪球抽样等方式进行配额。所以整个配额抽样在过程中会比较灵活、自主且主观。
配额抽样可以用如下图示简化理解:
3 #
到这里,我们会发现配额阅读抽样与分层阅读抽样都会对书本进行分类,接着抽取相应的章节开始阅读。但他们之间的区别在于,分层阅读抽样在分层之后通过简单随机抽样来确认章节被平均抽中的可能性,而配额抽样则是依赖于读者自己的偏好来选择 —— 从最开始的全书分类、到分好类之后的配额、再到对配额章节的选择,可以便利抽样、可以专家抽样也可以雪球抽样,整个过程体现出明显的读者个人倾向,这也是配额抽样的重要特征。
通过上述分析我们发现,配额阅读抽样并不需要严谨的抽样规则,整个操作过程更加主观、便捷。但配额抽样也会遭遇到一些问题,如果我们无法清晰的给到全书的分层标准,就无法清晰对全书分层进而无法配额。此外,又与配额抽样依赖于读者本人的自由选择,所以配额可能会受到阅读者本人认知偏见的影响,比如阅读者的阅读偏好、阅读者希望尽快通过阅读找到某些问题的答案,这样就无法将配额抽样的章节覆盖到整本书核心知识的理解上。