如何对一本书进行简单随机抽样阅读? #
1 #
为什么我们往往觉得买书容易看书难?一个容易忽视的细节就是书的厚度影响了我们的阅读决策,现在的书动不动都是10万字起步,当我想阅读一本书时,首先引入眼帘的是它的厚度,如果再叠加内容本身的阅读难度,大脑就会觉得书难读进而迟迟不愿再翻开它,或者像我一样,翻开的频率随着时间的推移而逐步减少直至降为零。
如何破解这个难题?经济学家维尔弗雷多 · 帕累托(Vilfredo Pareto)给我们带来了灵感,他指出,在大多数情况下,80% 的结果往往由 20% 的原因引发 (所以也被称为80/20 规则)。80/20 规则在生活中比比皆是:对于许多企业来说, 80% 的收入来自 20% 的客户、80% 的业绩来自 20% 的员工;对于个人来说,80% 的深厚友谊关系往往来自 20% 的朋友、80%的成果往往来自20%的努力。所以,80/20 原则提醒我们,关键是要找出这20%的至关重要的少数并专注于此,就能产生更好的成就。
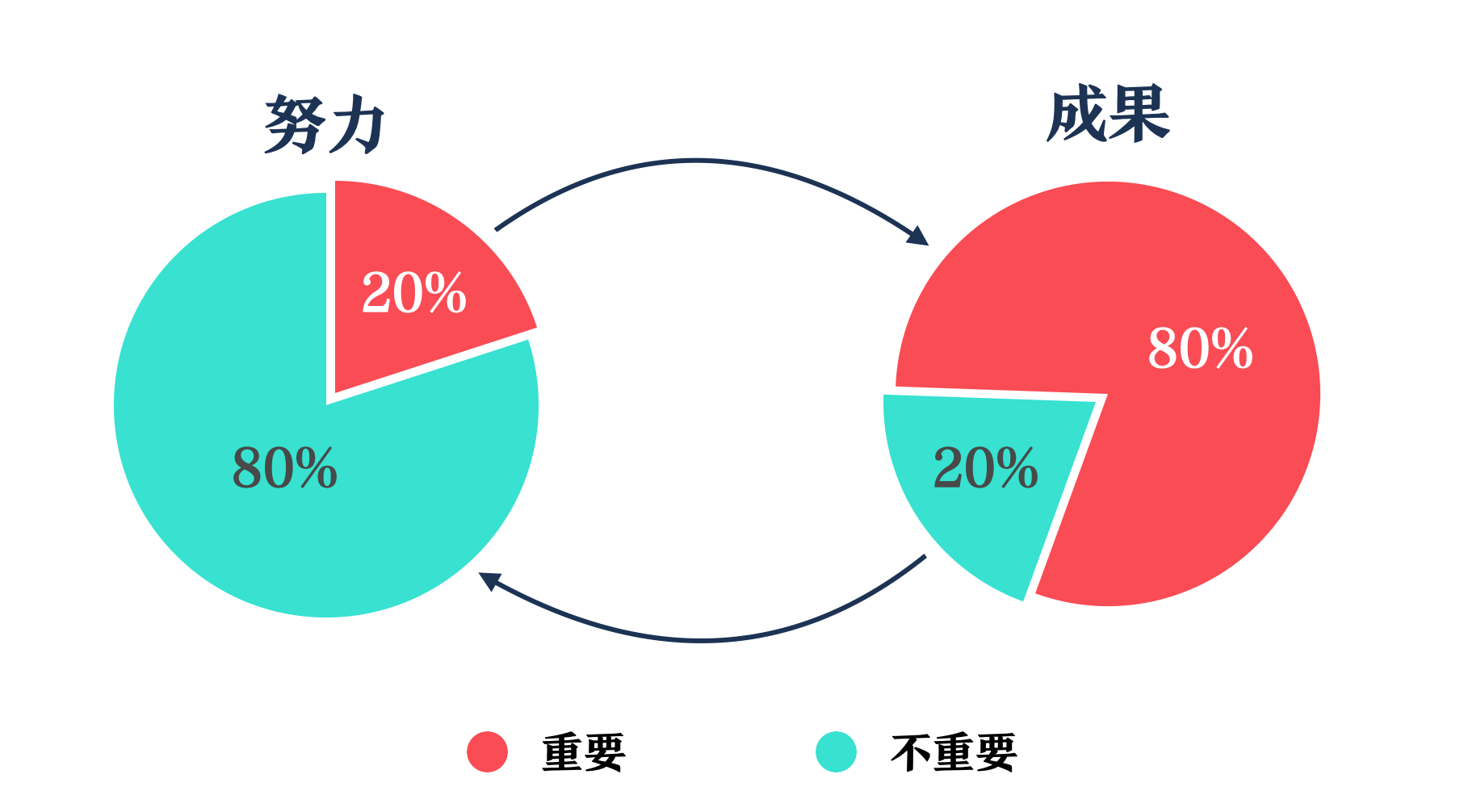
将80/20原则运用到阅读层面不难发现,一本书的20%往往代表了80%的内容权重。这就意味着,对于任意一本书,无论它有多厚,我们只要找到其中1/5的精华去读,就能大大降低大脑对阅读的畏难感。
(pic)
那么,当我们拿到一本书后,如何确认那20%的权重呢?
最简单的办法就是抽取一本书20%的章节,这称之为「简单随机抽样」:对于一本书不进行内容的解析判断,直接随机取样。
在具体计算过程中,还要考虑书中每页的文字密度,使用过Word的同学都知道,决定一页文字多少取决于两个要素,行距和字号:行距越小、字号越小,每页能够显示的内容就越多,反之亦然。
由于大多数书本的字号都在小四~五号字体之间,所以我们在随机抽样时将字号和行距形成的文字密度统一设定为1.1~1.6之间,那么一本书的核心章节就可以按如下公式进行计算:
核心阅读章节 = 书本章节总数 × 20% × 系数(1.1~1.6)
这里我们暂且将系数设为中位数1.3,所以就是:
核心阅读章节 = 书本章节总数 × 20% × 1.3
2 #
这里我们以《行为科学统计》这本书为示范进行简单随机抽样。
1. 核心章节计算 #
打开《行为科学统计》的目录页,我们发现这本书一共有19章:

我们将前面的公式代入:
《行为科学统计》核心章节 = 书本章节总数(19) × 20% × 中位系数(1.3)
= 19 × 20% × 1.3
= 4.94
≈ 5
所以我们现在知道,如果我们要对《行为科学统计》全书的知识进行相对完整的理解,最低需要随机抽样 5 章。
2. 随机抽样代入 #
我们打开统计网站
临床试验统计网 ,在首页点击标题栏 STATBOX:
在 新窗口标题栏继续点击 随机化-抽样-简单随机抽样
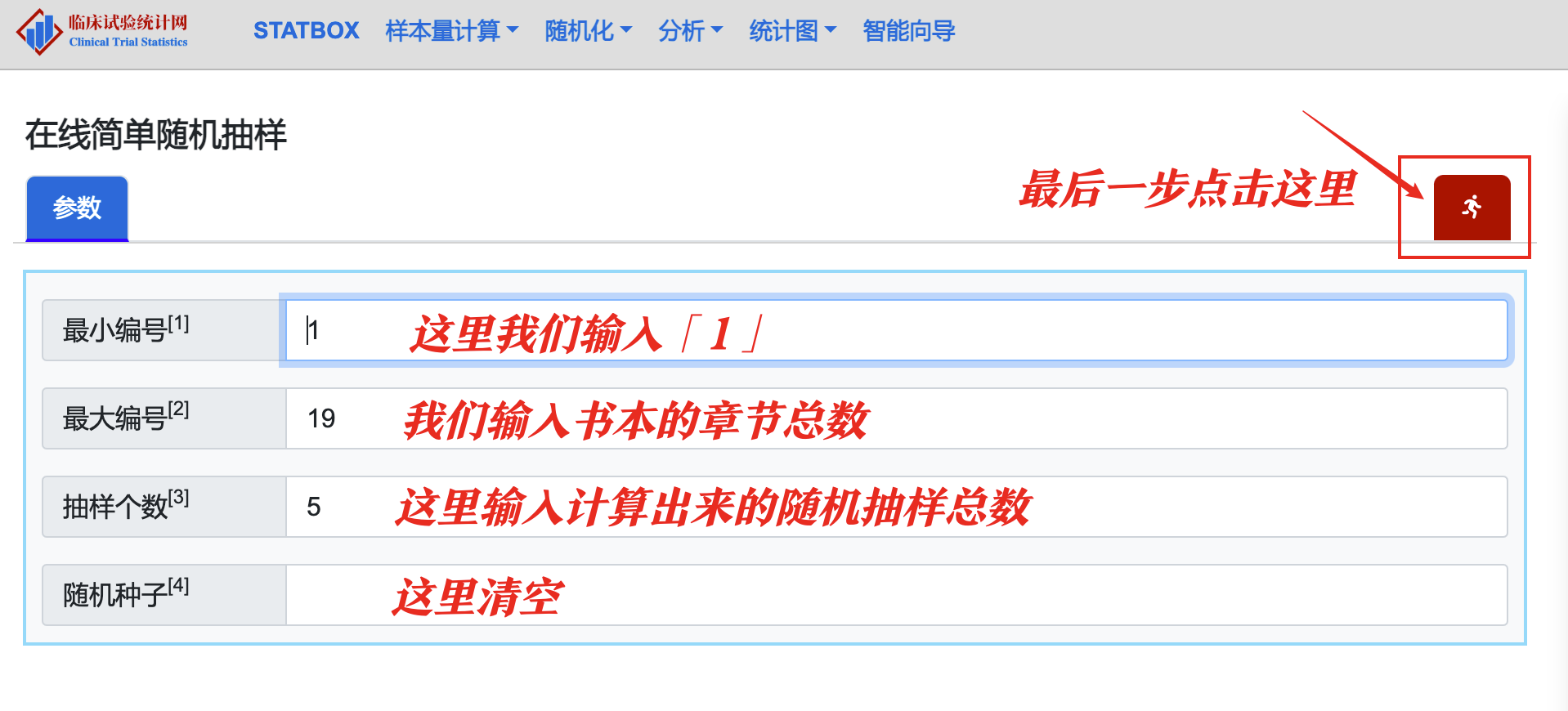
新弹出「在线简单随机抽样」页面,我们把最小编号、最大编号(《行为科学统计》的章节总数)、抽样个数(简单随机抽样的章节数量)填写(注意最后一步「随机种子」清空原始值留空),然后点击右上角的红色计算按钮。
这样就弹出了随机抽样的章节:
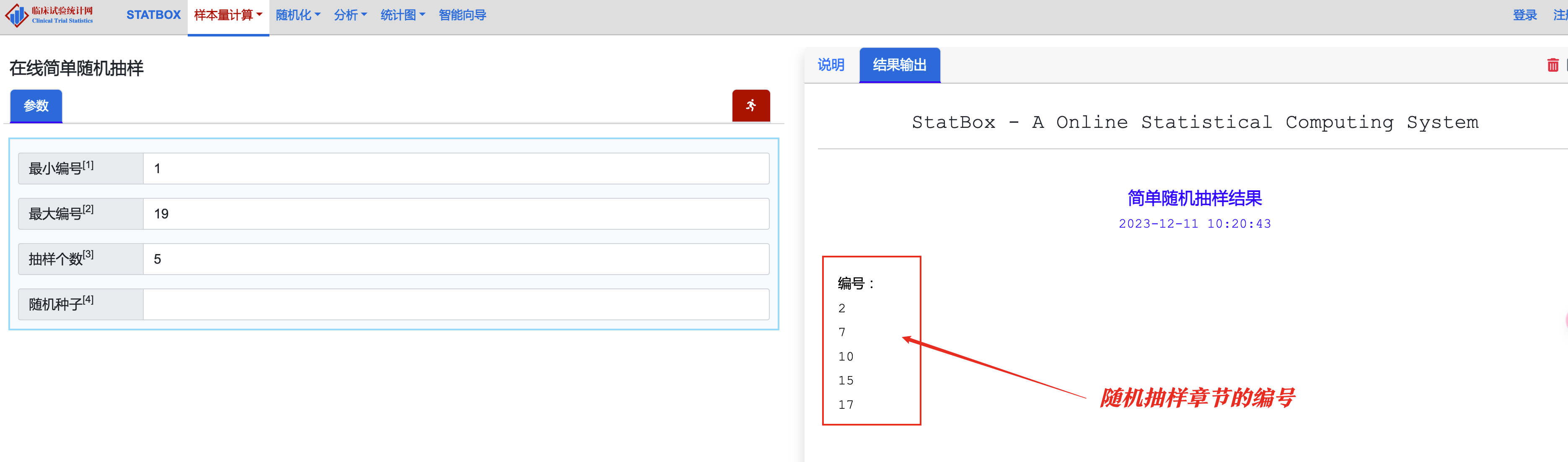
这时候,我们就翻开《行为科学统计》,着重阅读第2章、第7章、第10章、第15章以及第17章。不过这里需要留意,因为抽样结果具有随机性,所以如果我们在网站上进行第二次类似操作时,可能会出现不同的抽样章节。
到这里我们发现,对于书本的简单随机抽样,我们只需要做到两步即可:
- 根据全书的章节总数按照80/20原则进行随机抽样的章节数量计算。
- 将相关数据填入 临床试验统计网 ,得出首先阅读的章节。
3 #
到这里有的同学可能会问,这里的简单随机抽样结果具有极大的随机性,如果抽样出来的章节并非核心章节,这里的抽样还有什么意义?
其实,如果我们拿到一本自己比较陌生的书,我们暂时没有有效的方法确认这本书的核心章节时,这时候通过简单随机抽样可以让自己尽快激活自己阅读行为,不至于一直认为一本书太厚、太难读而陷入阅读瘫痪的窘境。而一旦激活了阅读行为,后面介绍的相关抽样方法又能进一步调整自己先前随机抽样的判断,形成对全书更深刻的认知与理解。所以,简单随机抽样阅读看似简单,其实它是整个抽样阅读的基础。
Ref:
《聪明的阅读者》