如何对一本书进行分层抽样阅读? #
1 #
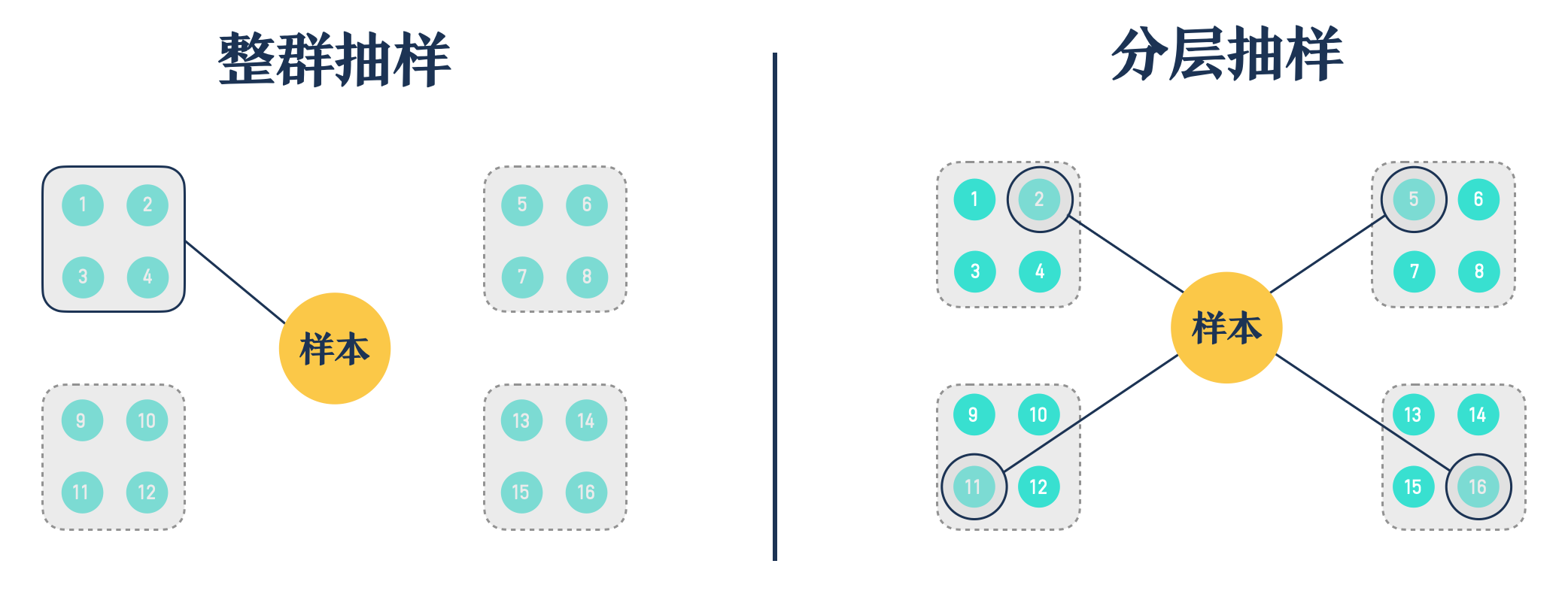
在前面提到了通过 整群抽样 方法,其核心是从全书中抽取一本书的一个「章节群」后开始阅读:
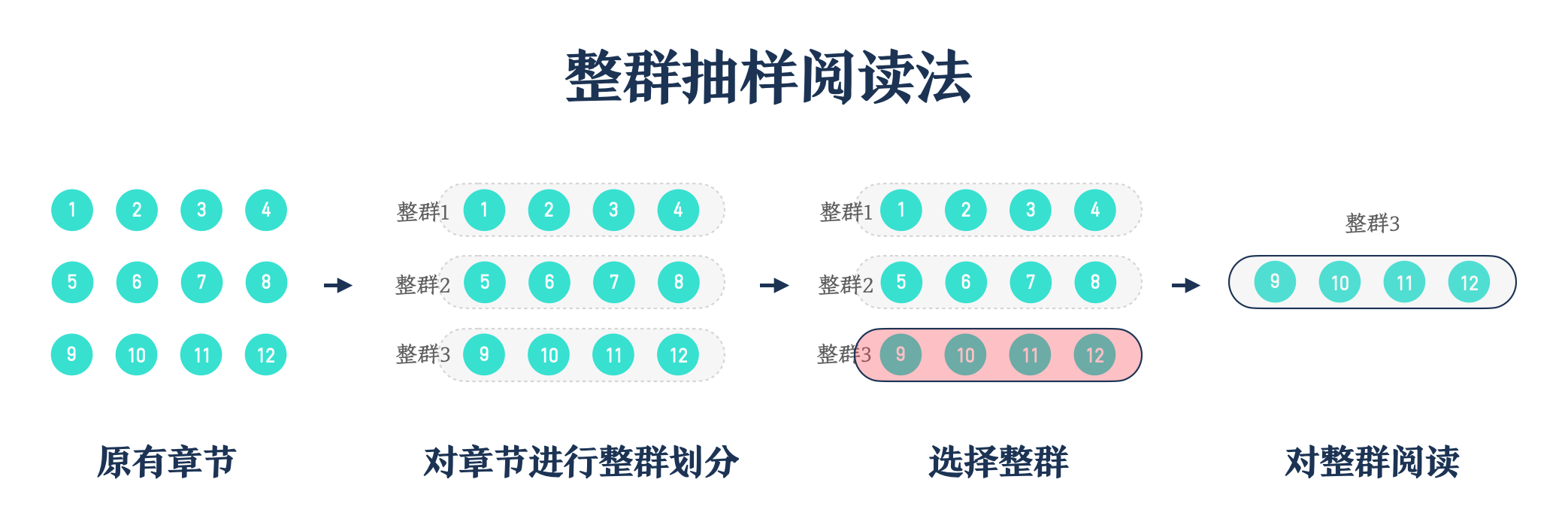
如上图所示,如果我们通过整群抽样最终选择了整群3,那么意味着整群1和整群2的章节信息将被我们放弃,而整群1和整群2累积章节数量是整群3 的2倍(以上只是示范,实际阅读中可能遭遇更多),所以单纯使用整群抽样对全书重要信息的遗漏可能比较明显。而我们又不可能对整群1和整群2的章节进行全部阅读,这时候我们如何降低整群抽样带来的信息遗漏的风险呢?分层抽样阅读可以帮助我们降低这种缺陷。
2 #
什么是分层抽样阅读? #
当我们拿到一本书后,我们首先确认这本书中有哪些不同的特征,再将整本书按归纳的特征划分成多个「特征章群」,然后借助简单随机抽样方法对每个特征章群进行章节抽样,最后对所有特征章群分别抽取了一个或多个章节,这些章节最后组成一个「小集合」,这样就可以进行文本细读了。
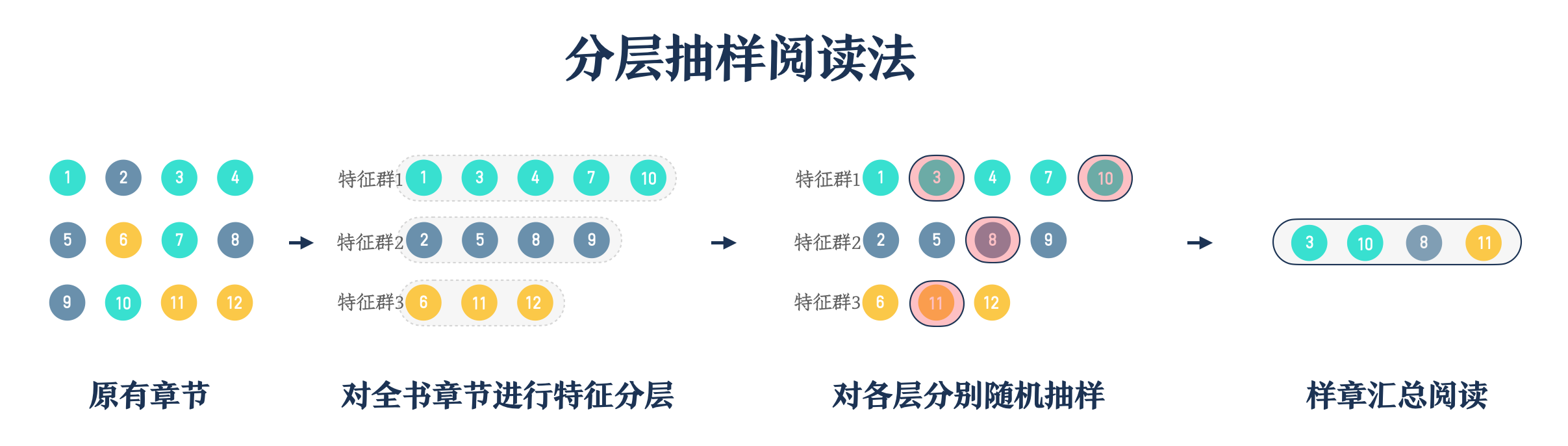
通过上图可知,分层抽样最关键的步骤在于第二步:对章节进行特征分层,其他步骤相对来说比较简单。那么我们可以通过什么方法分层呢?
在《聪明的阅读者》一书中,阳老师介绍了两种分层方法:参考前面整群抽样阅读方法,可以将特征分层也可以分层两个「显性」和「隐性」两个维度:
| 属性 | 分层方法 | 描述 | 示范 |
|---|---|---|---|
| 显性 | 人物身份/角色 | 对于书中出现的人物进行身份的差异化命名 | 作家、科学家、企业家 |
| 隐性 | 权重章节 | 根据代表全书关键思想的权重章节进行命名 | 核心章节、边缘章节 |
换句话说,对一本书进行分层抽样阅读的关键操作在于第二步 —— 对全书章节进行特征分层。
比如《人性实验》这本书,通过目录我们发现发现全书一共有28个章节,每个章节描述一个与社会心理学相关的研究:

针对这本书应该如何进行分层呢?
我们可以用 时间 来划分,因为全书章节默认以研究论文发表时间排序,所以我们就以时代线排序:
- 195x ~ 196x
- 197x ~ 198x
- 199x ~ 200x
- 201x ~
相关章节按年代分组如下::
| 序列 | 论文发表周期 | 章节 |
|---|---|---|
| 1 | 195x~196x | 1~6 |
| 2 | 197x~198x | 7~18 |
| 3 | 199x~200x | 19~25(排除23) |
| 4 | 201x~ | 26~28 +23 |
这样我们就将全书分成了4层,后面就可以在这4层中进行简单随机抽样,抽出章节开始阅读。
我们还可以根据 社会心理学所涉及到的领域 来划分,当我们找到主流社会心理学教材,分析目录后发现,社会心理学一般可以分成如下几个层面:
| 主题 | 描述 |
|---|---|
| 社会认知 | 如何我们理解、解释、记忆和使用关于社会世界的信息 |
| 社会影响 | 如何人们被他人的行为、态度、信念和存在所影响 |
| 人际关系 | 人们在人际互动中的行为和情感,例如吸引力、友谊、爱情等 |
| 群体行为和社会身份 | 我们在群体或社区中的行为以及我们如何理解和应对我们的社会身份 |
| 偏见和刻板印象 | 我们对特定群体的固有认知和情绪偏见,以及如何形成和影响这些偏见 |
这就相当于获得了社会心理学所涵盖的5大主题,这五个主题就相当于找到了阅读社会心理学书籍的「抽样层」。
那么这时候,我们其实可以将本书28个章节划分到五大主题中:
| 序列 | 主题 | 章节 |
|---|---|---|
| 1 | 社会认知 | 3/8/10/14/16/20/21/22/23/27 |
| 2 | 社会影响 | 1/2/4/5/6/17 |
| 3 | 人际关系 | 7/13/18/19 |
| 4 | 群体行为和社会身份 | 9/11/12/25/26/28 |
| 5 | 偏见和刻板印象 | 15/24 |
这样我们就得出了《人性实验》一书全部章节在社会心理学领域涉及到的章节覆盖数量:
| 序号 | 主题 | 章节覆盖数量 |
|---|---|---|
| 1 | 社会认知 | 10 |
| 2 | 社会影响 | 6 |
| 3 | 人际关系 | 4 |
| 4 | 群体行为和社会身份 | 6 |
| 5 | 偏见和刻板印象 | 2 |
通过上图我们发现,对于《人性实验》这本书而言,五大社会心理学领域涉及到的篇幅是不同的,如果我们这时候对五大主题各选取1章来阅读,就会产生部分主题(比如社会认知模块)抽样太少的偏差,而这时候我们就可以借鉴之前学到的简单随机抽样方法,分别对这五个主题的章节进行随机抽样,比如这样:
| 序号 | 主题 | 章节抽样数量 |
|---|---|---|
| 1 | 社会认知 | 3 |
| 2 | 社会影响 | 2 |
| 3 | 人际关系 | 1 |
| 4 | 群体行为和社会身份 | 2 |
| 5 | 偏见和刻板印象 | 1 |
这样我们就得到了从五大模块的章节分组中进一步得到了9个章节,相当于全书约30%占比,相比前面的整群分组阅读方法,我们这次得到的章节对社会心理学领域涉及到的五大模块都能覆盖,这种分组方式,就可以称之为「分层抽样」。
当然,我们不止通过主题来分组,还可以通过其他方法进行快速分组:
| 属性 | 分层项 | 说明 | 示例 |
|---|---|---|---|
| 显性 | 身份/角色 | 对于书中出现不同身份或属性的人/事/物进行分类汇总 | 身份A、身份B、…… |
| 显性 | 模块分组 | 封面封底、目录、译者序、推荐序、自序、前言、后记明示的全书分组 | 分组1、分组2、…… |
| 显性 | 时间分组 | 对于书中出现的章节代表的不同时间线进行分组 | 时间1、时间2、…… |
| 显性 | 空间分组 | 对于书中出现章节代表的不同空间线进行分组 | 空间1、空间2、…… |
| 显性 | 关键词分组 | 对于书中出现的高频关键词进行排名的分组 | 关键词1、关键词2、…… |
| 显性 | 篇幅分组 | 将书中章节占用全书的篇幅进行分类汇总 | 全书篇幅TOP1/2/3,其他…… |
| 隐性 | 论文应用 | 书中作者自己论文引用最多占比,书中作者他引论文最多占比 | 全书自引/他引论文TOP1/2/3,其他…… |
在分层阅读的操作中,需要注意的有两点:
- 在第二步将全书章节按照既定标准分配到每个标准层时,每个标准层都应该是互斥关系,也就是分组后的章节群之间不会存在重叠,但又共同完整覆盖了整本书的内容。
- 将全书分好层之后,要留意每层章节的数量差异,避免分层后直接各调一章开始阅读,而是要采取 80/20 原则进行差异化抽样,以确保最终抽样的数量能代表各自所属的章层。
3 #
相比简单随机抽样,分层抽样既关注整体(全书分层)又注重局部(每层抽样),所以它相对来说抽取的章节更具多样性,确保了样章的差异化,从而有助于更好的理解全书的内容。如果看过上篇 整群章节抽样 的介绍,会发现分层章节抽样与整群章节抽样都有将章节组成「章群」的步骤,所以它们看起来可能比较相似,但细致分析依然有两个明显差异:
-
对全书进行整群章节抽样的标准相对显性从而容易获取。比如在封面、封底、目录、导言、自序、他序、第一章、后记等模块就能相对轻松的找到整群抽样的分组信息,而分层章节对读者的抽样能力要求稍高,涉及到对全书的概览能力、书中引用文献的分析能力、作者审美偏好的判断能力等等。所以找到一个详尽而明确代表整本书的分层抽样标准具有一定的挑战性,如果无法科学合理地对全书的层级进行分类,最终可能导致随机抽样的章节出现偏差,从而对全书的理解产生误判;此外,如果设定的分层标准导致某些章节既属于A层级又属于B层级时,那么最后的抽样结果可能对全书的正确理解造成偏离。相比较其他抽样方法,分层抽样需要更多的尝试与练习。
-
整群抽样的目的是降低抽样复杂性以提高抽样效率,所以整群分类的操作相对简单而且快速,而分层抽样阅读的目的是提高抽样精度以减少误差,所以它创建的章节群中的章节有着明显的共同特征。整群章节抽样后需要对整个章群进行阅读;而分层抽样的目标是获取差异化属性的各个章节群,然后再从各章节群中抽样出少量代表该章群样本的章节,最终逐个汇总起来文本细读。因此,当我们拿到一本书后,如果暂时没有时间或能力对这本书进行精细化分类,那么我们不妨借助书中已有的显性信息采用整群抽样的方法,这样便于快速激活自己的阅读行为,而如果时间足够,就可以学习对全书核心章节判断的方法对该书进行更加精细化的分层抽样。
分层章节抽样与整群章节抽样差异如下图示简化: