如何对一本书进行整群抽样阅读? #
1 #
我们在前两篇抽样方法中知道,「简单随机抽样」和「等距抽样」不考虑对书本内容的阅读而直接抽样,即「先抽样再阅读」,但我们也会发现,很多书会主动向我们告知全书的组成架构,相比我们一上来就对全书进行抽样来说,这些信息无疑更具有参考价值。所以在我们抽样之前就发现了类似信息,我们就要主动借助这些信息协助我们更好的抽样。
那么,这种信息应该如何识别呢?
从这些信息被识别出来的难易度而言分两种,一种偏显性,一种偏隐性。
| 章节分组类别 | 说明 |
|---|---|
| 偏显性 | 书中有明显的分组说明 |
| 偏隐性 | 需要我们自己去分析与挖掘的章节分组信息 |
在整群抽样中,对全书进行分类的标准整体而言偏显性,因此往往比较容易直接从书中找到相关的提示。
最明显的就是作者直接通过目录告知全书结构,比如《如何达成目标》一书,全书一共13章,作者直接在目录中将其划分为「准备就绪、预备开始、行动起来」三个部分:

再比如莉莎 · 费德曼 · 巴瑞特教授(Lisa Feldman Barrett)的《情绪》一书一共有13章,虽然在目录上没有像《如何达成目标》一样体现出分类,但她在前言部分对这本书分成了四组:

这样我们就不用一开始通过随机抽样或等距抽样来抽取章节了。
再比如《行为科学研究方法》这本书,在「译者序」中,将全书16章分成了五大部分:

同样,我们可以参考译者对该书的划分建议。
又比如《人是如何学习的-II》,全书一共10章,在「中文序」中将全书分成七大主题:

通过上述样例我们发现,当我们拿到一本书时,其实有很多地方都对一本书的架构有相关介绍:封面、封底、译者序、推荐序、自序、目录、前言、第一章、后记等位置值得我们花一点点时间留意,这些地方往往透露了全书整群分类的关键信息,可以帮助我们快速了解一本书的权重。对这些信息的掌握与利用,往往能起到四两拨千斤的作用。
除此之外,如果一本书中没有找到类似的分组信息,我们也可以自己灵活且快速地对全书进行分组,比如《聪明的阅读者》提及的对《认知尺度》一书中的作者的身份进行分类:作家、科学家、企业家,而后快速选择相应的章节阅读。
……(其他案例)……
2 #
到这里我们发现,整群抽样的操作整体可以分成两个步骤:
1. 寻找对全书章节进行分组的信号 #
对全书章节进行分组可以分成两种,第一种是他人进行的分类,比如作者、译者、作序者在封面封底、目录、推荐序、译者序、自序、导读、前言、后记等地方对全书进行的结构化分组;第二种由我们自己对全书进行分类。我们借助这些信息快读将全书分成由多个章组合而成的章群。
2. 使用简单随机抽样法抽取要阅读的章群 #
我们将全书分成了多个章群后,会发现有的章群章节多、有的章群章节少,这时候我一般选择包含章数最多的章群优先进行阅读,以保证章群对全书的最大程度覆盖,比如前面介绍的《如何达成目标》一书有3个部分,我们就优先阅读篇幅最大的第二部分;如果我们抽取的章群数量差不多,比如《人是如何学习的-II》一共有7个主题,这些主题包含的章节数量大体一致,我们就在从中通过随机抽样方法抽出一个主题阅读。
需要注意的是,由于我们最终希望抽取一个章节进行阅读,而
临床试验统计网 不支持抽取数量为1的简单随机抽样:
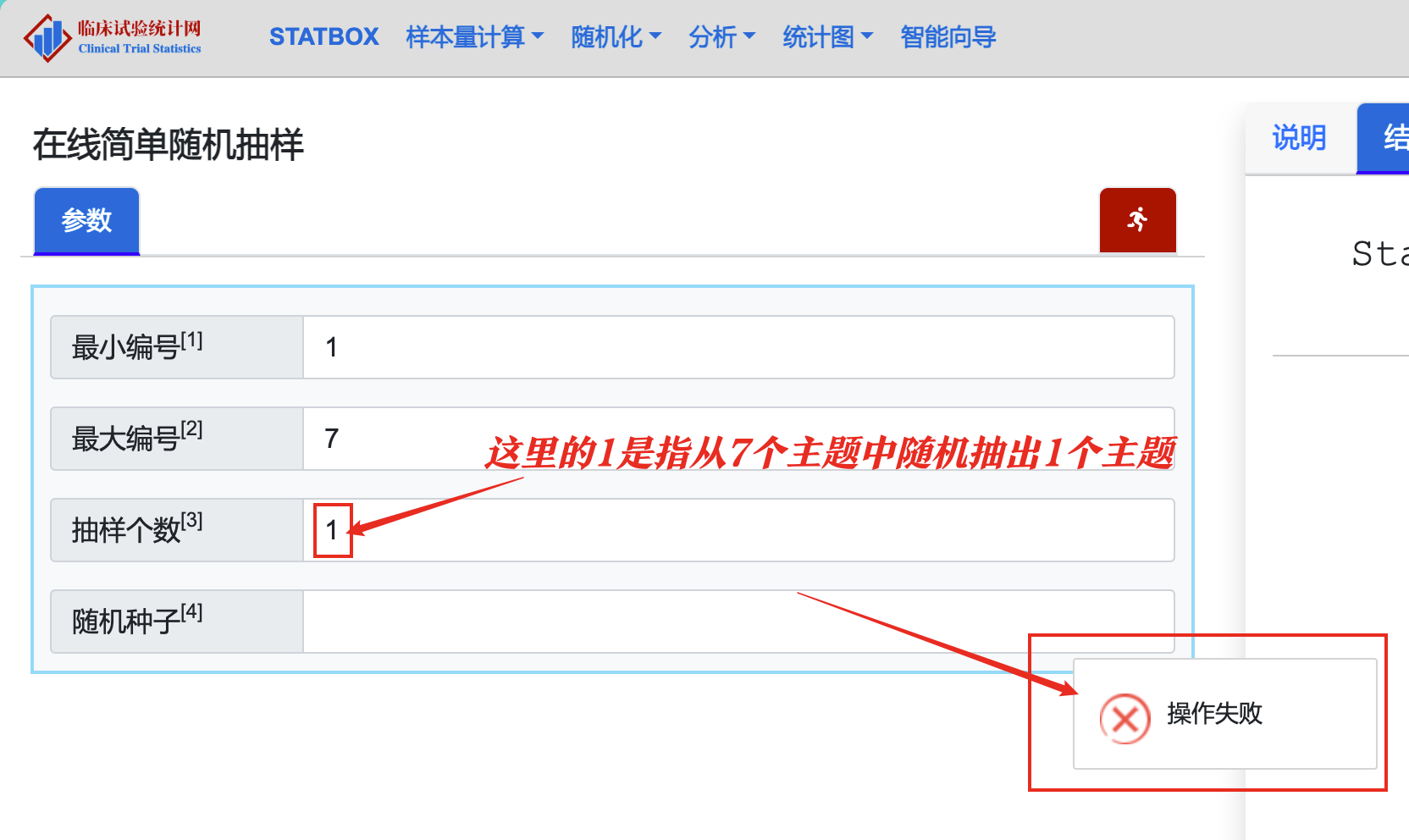
所以我们如果希望自己从选取的章节群中随机抽样1个章节群,可以尝试将上面的「抽样个数」填成 2,然后从抽出的数字中随机选一个开始阅读即可。
3 #
到这里我们发现,整群抽样的关键在于对全书的章节提前分组,一旦确认了章节的组别,就能很好抽取章节。与「简单随机抽样」操作方法类似,唯一区别在于我们通过简单随机抽样抽出来的是多个章节,而这时候我们只需要抽取其中1个群章即可,所以我们最终需要阅读的不是一个一个的章节,而是一个或多个章节群。
整群章节抽样流程细化如下:
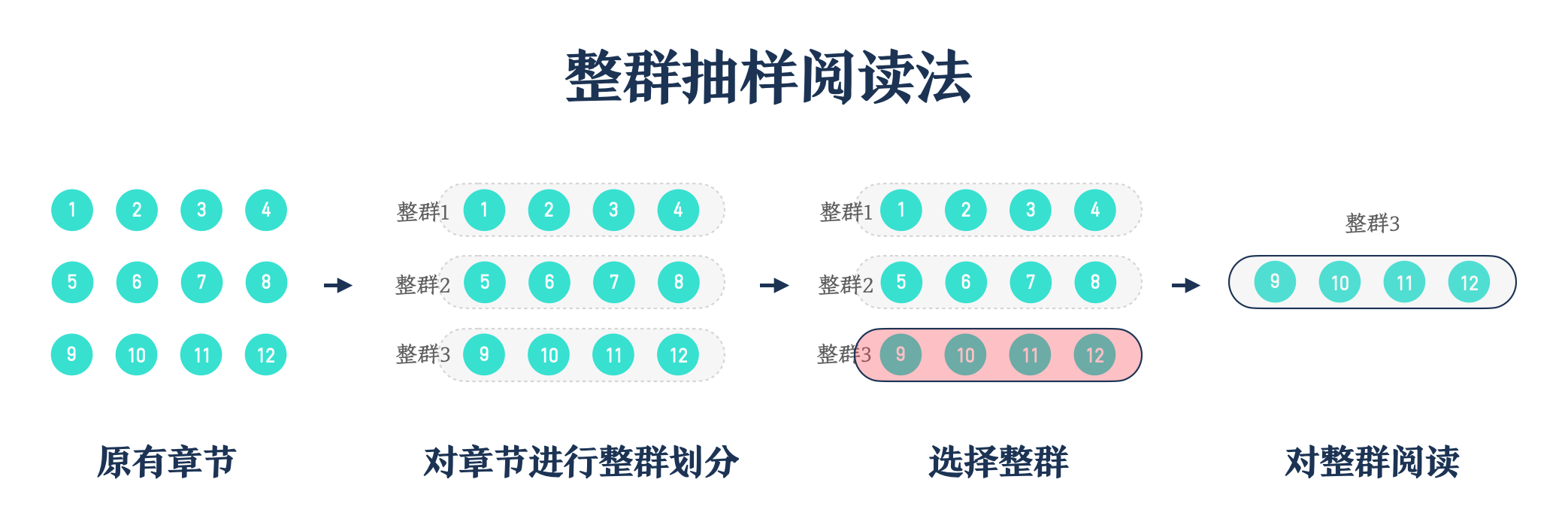
4 #
整群抽样相比简单随机抽样与等距抽样,有三个明显优点:
- 整群抽样抽取的一般是多个章节组成的大样本,而非彼此独立的单一章节,所以大幅度降低了全书章节抽样的时间与精力成本。
- 整群章节抽样大都基于书中目录、序言、导言、后记等给到相对明显的提示对全书进行结构划分(还可通过人物的身份、角色、职位、特质、所处的国别、空间、年龄段等维度进行划分),所以整群的建立速度相对迅速。
- 一旦建立了章群的结构,就能马上对章群展开文本细读工作,相对传统从头看到尾的阅读习惯,整群抽样后更强调对文本阅读的深度理解,容易对章群形成更深入的认知。
当然,整群抽样也存在着一些缺陷:
- 无论我们整群抽样的阅读章节是基于篇幅占比还是随机抽样产生,都相当于「有舍有得」 —— 得到了一个完整的章群,舍去了对未选中章群的阅读,而这些未选取的章群中可能包含着全书核心信息的部分或者一些不同于已选章群的差异化信息,比如如果抽取的章节群内某一章节与其他章群的一个或多个章节存在特定关联,而整群抽样的阅读就有可能觉察不出这种外在关系。在这种状况下,提高整群抽样的数量可能是一个可以尝试的方案,但也带来了更多增细阅读的成本。
- 如果整群抽样前发现书中未能有关于全书结构的分类信息,而且也较难对全书进行结构化分类,这就带来了整群抽样的难度,比如可能需要引入后续「分层章节抽样」的策略,或者将不同抽样策略进行叠加以获得更精准的权重。